


StoryLAB
Experimentación en torno a las nuevas narrativas y su impacto en el conocimiento abierto e inclusivo.

Diccionario de gestión de proyectos
He actualizado el diccionario de gestión de proyectos que publiqué hace un tiempo en la sección de Recursos de mi web. Originalmente se trataba de un diccionario inglés-castellano, pero comentarios de estudiantes de algunos [...]

Glosario de comunicación audiovisual
El vocabulario asociado a la comunicación audiovisual puede resultar algo... sorprendente. No sólo por la profusión de anglicismos (cosa nada infrecuente en cualquier rama de la tecnología), sino también por la readecuación semántica de [...]

Taller de herramientas de comunicación
Taller gratuito en línea para que Pymes y personas autónomas conozcan tres útiles herramientas TIC: Slack, Bitrix24, Fleed. Información La Oficina Acelera Pyme onTech InnovationSitio web www.acelerapymeontech.comAcceso [...]

Herramientas de comunicación para la PYME
Introducción En el actual panorama de los negocios, las herramientas de comunicación corporativa cumplen varias funciones que van más allá de la transferencia de noticias entre los [...]

Desglosando el camino al éxito en gestión de proyectos: la EDT
La gestión de proyectos no es una misión sencilla, pero afortunadamente hay bastantes instrumentos que podemos incorporar a nuestra caja de herramientas y que nos ayudarán a no desviarnos del camino al éxito. Entre [...]

Modelo INVEST: checklist
Guía para ayudar a aplicar el modelo INVEST en la redacción de historias de usuario. Información El modelo INVEST es un conjunto de criterios que deberían [...]
(con C entre paréntesis)
Diccionario de gestión de proyectos
He actualizado el diccionario de gestión de proyectos que publiqué hace un tiempo en la sección de Recursos de mi web. Originalmente se trataba de un diccionario inglés-castellano, pero comentarios de estudiantes de algunos de mis cursos me han hecho ver que la traducción debería ir más allá. Muchos términos de uso habitual cobran un nuevo sentido en un campo de conocimiento técnico, que es de lo que se trata la gestión de proyectos. Por lo tanto, un glosario de expresiones usadas en esta disciplina puede ser de ayuda.
Continuaré ampliando o profundizando las definiciones. Seguramente se me han pasado por alto muchos términos, así que invito a enviarme ideas.
Diccionario de gestión de proyectos
Puedes consultar el diccionario en la sección de Recursos.
Glosario de comunicación audiovisual
El vocabulario asociado a la comunicación audiovisual puede resultar algo… sorprendente. No sólo por la profusión de anglicismos (cosa nada infrecuente en cualquier rama de la tecnología), sino también por la readecuación semántica de muchas palabras de uso cotidiano.
La intención de este glosario es facilitar la inmersión en este lenguaje.
ángulo de cámara
analepsis
animación
atrezzo
audiovisual
autocue
b-roll
banda sonora
barrido
biblia audiovisual
biblia transmedia
bitrate
cámara lenta
cámara rápida
chroma key
clip de vídeo
código de tiempo
composición de escena
composición fotográfica
comunicación audiovisual
contracampo
cortometraje
croma
curva de color
doblaje
dolly
dolly zoom
dron o drone
edición
efectos especiales
eje de la acción
eje óptico
elipsis
emplazamiento de cámara
escaleta
escena
escorzo
efectos de sala o efectos foley
espacio fílmico
etalonaje
flashback
flashforward
fade in
fade out
formato
foto cinemática
fotograma
frame
fuera de campo
fundido
FX
gran plano general
guion
guion gráfico
guion literario
guion técnico
guion transmedia
HDR
idea original
iluminación
inserto
largometraje
locación
log-line o logline
matte painting
mediometraje
minutaje
mise en scène
montaje
motion graphics
multimedia
noche americana
paneo
panorámica
pista de audio
plano americano
plano audiovisual
plano cenital
plano contrapicado
plano detalle
plano general
plano inclinado
plano maestro o plano master
plano medio
plano medio corto
plano medio largo
plano picado
plano recurso
plano secuencia
plano subjetivo
precuela
preproducción
primer plano
primerísimo primer plano
prolepsis
profundidad de campo
posproducción o postproducción
raccord
reboot
remake
render
renderizar
resolución de imagen
roll
secuela cinematográfica
secuencia
sinopsis cinematográfica
slow motion
sonido diegético
sonido extradiegético
stop motion
storyboard
streaming
tag-line o tagline
teleprompter
tiempo de exposición
time code
time-lapse o timelapse
toma cinematográfica o toma audiovisual
trailer
transición de escena
transmedia
travelling
VFX
video o vídeo
zoom
zoom in
zoom out
Este recurso es un trabajo en progreso. Seguramente iré sumando terminología en la medida de que los términos se hagan presentes en mi trabajo de investigación, docencia o consultoría. Por otra parte, cierto es que el campo audiovisual fluye y evoluciona con rapidez, con lo cual nuevos conceptos no paran de emerger.
Taller de herramientas de comunicación
Taller gratuito en línea para que Pymes y personas autónomas conozcan tres útiles herramientas TIC: Slack, Bitrix24, Fleed.
Información
La Oficina Acelera Pyme onTech Innovation1, junto a la consultora malagueña Arelance,2 ha organizado un taller online, gratuito, orientado a Pymes y personas autónomas, al cual he sido invitada como ponente. En el taller se darán a conocer las ventajas de las tres TIC que he reseñado en este artículo (Slack, Bitrix24 y Fleep). También haremos una comparación entre herramientas y explicaremos los requisitos de implementación y de integración.
Más información
Notas y referencias
Herramientas de comunicación para la PYME
Introducción
En el actual panorama de los negocios, las herramientas de comunicación corporativa cumplen varias funciones que van más allá de la transferencia de noticias entre los públicos. Tienen también un impacto positivo en la productividad, puesto que facilitan el trabajo colaborativo y el intercambio de información en tiempo real y de forma interactiva, así como el content marketing y los procesos de branding.
Hoy en día, no sólo las grandes corporaciones pueden beneficiarse de las TIC; las PYME también encuentran una gran oportunidad en el mundo digital para mejorar la colaboración interna o potenciar la relación con sus diversos públicos. Muchas son las empresas desarrolladoras de software que ofrecen planes especiales o incluso aplicaciones específicas para las pequeñas empresas o los profesionales autónomos.
A continuación, reseño tres de las TIC más efectivas, diseñadas para adaptarse a las necesidades y presupuestos de las PYME.
Slack
 No por casualidad, Slack se ha convertido en sinónimo de comunicación interna para una gran cantidad de empresas de todo tipo y tamaño. Se trata de una tecnología con una baja curva de aprendizaje -con una interfaz realmente intuitiva- y está especialmente diseñada para integrarse con una amplia gama de herramientas de terceros, como Google Drive, Trello, Jira, Asana, etc.
No por casualidad, Slack se ha convertido en sinónimo de comunicación interna para una gran cantidad de empresas de todo tipo y tamaño. Se trata de una tecnología con una baja curva de aprendizaje -con una interfaz realmente intuitiva- y está especialmente diseñada para integrarse con una amplia gama de herramientas de terceros, como Google Drive, Trello, Jira, Asana, etc.
Una de las grandes fortalezas de Slack es que permite crear canales específicos para los distintos equipos o proyectos en los que se esté trabajando. Dichos canales pueden ser abiertos para toda la empresa o privados, para conversaciones confidenciales. Además, Slack ofrece el servicio de mensajería directa, ya sea para conversaciones uno a uno o para grupos. Encontrar mensajes, archivos o personas resulta notablemente fácil gracias al buscador propio de esta herramienta.
Los usuarios pueden compartir documentos y contenido multimedia, tanto en los canales abiertos como en las conversaciones privadas.
Otro aspecto interesante es la posibilidad de crear bots personalizados para así automatizar tareas rutinarias y ofrecer respuestas automáticas.
Por último, cabe destacar la capacidad de escalabilidad de esta herramienta: si la empresa crece, ella también lo hace. Todas sus funciones se adaptarán de manera eficiente a unos volúmenes crecientes de trabajo.
Bitrix24

Hay que entender Bitrix24 como una plataforma integral de gestión empresarial. Combina funciones de comunicación, gestión de proyectos y de tareas, CRM, gestión de RRHH, gestión documental, creación de sitios web o de una landing page y más. En otras palabras, es una solución ideal para empresas que estén buscando centralizar sus operaciones, de modo de no depender de múltiples herramientas dispersas.
Con respecto a la comunicación interna, también tiene gran potencial. Su chat en tiempo real o el canal de videollamada son sólo un par de las funciones que ofrece.
Bitrix24 cuenta con herramientas integradas de SEO y plantillas personalizables.
Y no nos olvidemos de mencionar su versión de app móvil, tanto para iOS como para Android.
Fleep
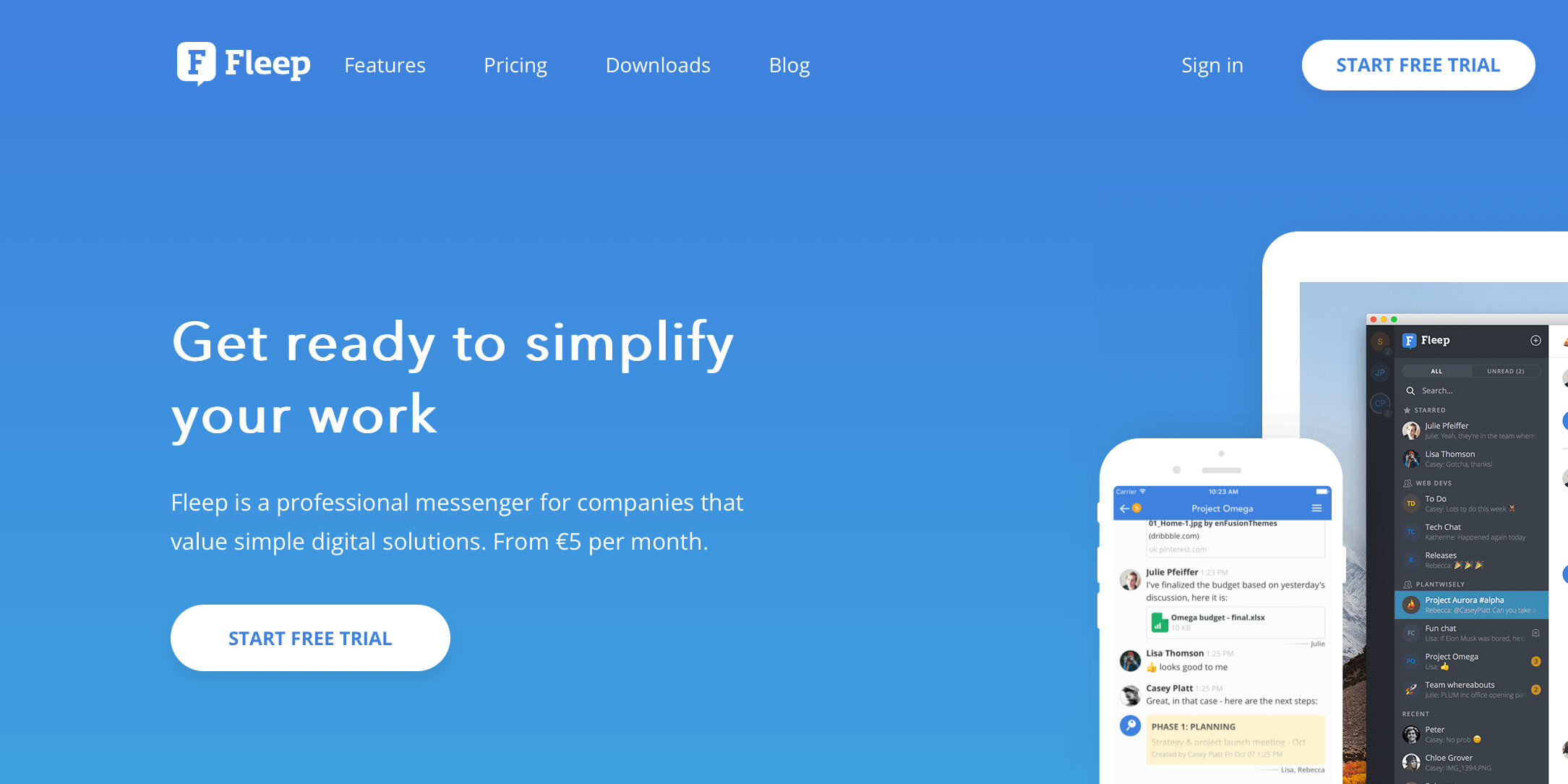 Esta plataforma de comunicación corporativa permite a la empresa relacionarse y colaborar con cualquier tipo de usuario, tenga o no una cuenta de Fleep. Una de sus características destacadas es el sistema de mensajería, que permite organizar las conversaciones o chats por proyectos, temas o equipos de trabajo. En el chat los usuarios pueden crear, asignar y seguir tareas.
Esta plataforma de comunicación corporativa permite a la empresa relacionarse y colaborar con cualquier tipo de usuario, tenga o no una cuenta de Fleep. Una de sus características destacadas es el sistema de mensajería, que permite organizar las conversaciones o chats por proyectos, temas o equipos de trabajo. En el chat los usuarios pueden crear, asignar y seguir tareas.
Fleep es compatible e integrable con herramientas de productividad y de gestión de proyectos, como la suite de Atlassian o de Google.
Desglosando el camino al éxito en gestión de proyectos: la EDT
La gestión de proyectos no es una misión sencilla, pero afortunadamente hay bastantes instrumentos que podemos incorporar a nuestra caja de herramientas y que nos ayudarán a no desviarnos del camino al éxito. Entre esos instrumentos, la estructura de desglose del trabajo o EDT presenta numerosas cualidades que facilitan la planificación, la dirección y el seguimiento detallado del progreso de un proyecto.
¿Qué es eso de la EDT?
Podemos concebir la estructura de desglose del trabajo (EDT) como un mapa detallado y jerárquico (sobre todo, jerárquico) de las tareas que componen un proyecto. El desglose de tareas se va realizando de manera secuenciada, partiendo del nivel superior en que encontramos el nombre o descripción sumaria del objetivo del proyecto, pasando por las fases o componentes del proyecto y hasta llegar a la especificación de los paquetes de trabajo, que constituyen el nivel inferior de toda esta estructura jerárquica.
Una estructura de desglose de trabajo (EDT), también conocida por WBS (Work Breakdown Structure) por sus siglas en inglés, es la descomposición de un proyecto que está organizado en varios niveles. En otras palabras, es una forma más sencilla de ver los entregables que hay que hacer para poder procesarlas.1
El desglose de tareas y subtareas se representa en una lista multinivel o, de preferencia, en una matriz gráfica, que servirá para ilustrar el alcance completo del proyecto. Una vez contemos con esta matriz desglosada se nos facilitará notablemente la asignación de responsabilidades y recursos, así como la confección del cronograma.
Componentes fundamentales de la EDT
Hay que tener en cuenta que la EDT debe siempre adaptarse a las características de cada proyecto. De todas maneras, hay ciertos elementos fundamentales, que no podrán faltar nunca en ninguna EDT y son los siguientes.
1. Fases del proyecto
El primer paso para elaborar la EDT consiste en identificar las fases fundamentales del proyecto. O sus componentes fundamentales, si se trata, por ejemplo, de un proyecto tecnológico iterable. Cada una de estas fases representa uno de los hitos del ciclo de vida del proyecto.
2. Entregables
Para cada fase se definirán unos entregables concretos. Recordemos que -de acuerdo con las especificaciones del PMI y el PMBOK2– la EDT debe estar orientada a los entregables.
3. Tareas y subtareas
Para cada fase del proyecto se definen las tareas necesarias para conseguir los objetivos y los entregables respectivos. Dichas tareas se subdividen en subtareas hasta llegar a un nivel de especificidad tal que resulta sencillo asignarles recursos y responsables.
4. Códigos de Identificación
Cada elemento de la EDT recibe un código único, que lo identifica y que facilita la organización y la referencia rápida. El propósito de estos códigos es propiciar una comunicación eficiente entre los miembros del equipo y los stakeholders.
Algunos ejemplos
Vamos a ver cómo se aplicaría el desglose de tareas en tres tipos de proyectos diferentes: un proyecto de desarrollo de software, la planificación de un evento de marketing y una investigación social.
Proyecto 1: Desarrollo de software
1.0 Desarrollo de aplicación de gestión de tareas
1.1. Inicio del proyecto
1.1.1. Reunión de inicio
1.1.2. Definición de objetivos
1.1.3. Planificación inicial
1.2. Análisis y diseño
1.2.1. Investigación de mercado
1.2.2. Definición de requisitos
1.2.3. Reunión con usuarios
1.2.4. Documentación de requisitos
1.2.5. Diseño de la interfaz
1.2.6. Prototipo de la interfaz
1.2.7. Revisión del diseño
1.3. Desarrollo
1.3.1. Configuración del entorno de desarrollo
1.3.2 Desarrollo del backend
1.3.2.1 Creación de la base de datos
1.3.2.2 Implementación de la lógica de negocio
1.3.3 Desarrollo del frontend
1.3.3.1 Diseño de pantallas
1.3.3.2 Implementación de la interfaz de usuario
1.4. Pruebas
1.4.1 Pruebas unitarias
1.4.1.1 Pruebas del backend
1.4.1.2 Pruebas del frontend
1.4.2 Pruebas de integración
1.4.3 Pruebas de usuario
1.4.3.1 Pruebas de aceptación
1.4.3.2 Retroalimentación de usuarios
1.5. Implementación
1.5.1 Despliegue en ambiente de producción
1.5.2 Capacitación de usuarios
1.5.3 Resolución de problemas post-implementación
1.6. Cierre del proyecto
1.6.1 Evaluación del proyecto
1.6.2 Documentación final
1.6.3 Lecciones aprendidas
Proyecto 2: Organización de un evento de marketing
2.0 Lanzamiento de Marca XYZ
2.1. Inicio del proyecto
2.1.1 Reunión inicial con cliente
2.1.2 Definición de objetivos y alcance
2.1.3 Creación del equipo de planificación
2.2. Planificación del evento
2.2.1 Investigación de la marca
2.2.2 Establecimiento del presupuesto
2.2.3 Selección del lugar del evento
2.2.3.1 Visitas a posibles locaciones
2.2.3.2 Contratación del espacio
2.2.4 Desarrollo del concepto del evento
2.2.4.1 Creación del tema y mensaje
2.2.4.2 Diseño de la identidad visual del evento
2.3. Logística
2.3.1 Gestión de invitados
2.3.1.1 Creación de la lista de invitados
2.3.1.2 Envío de invitaciones
2.3.2 Gestión de proveedores
2.3.2.1 Selección de catering
2.3.2.2 Contratación de servicios de audio y video
2.3.3 Planificación del transporte
2.3.3.1 Coordinación de transporte para invitados VIP
2.3.3.2 Establecimiento de estacionamiento
2.4. Marketing y promoción
2.4.1 Estrategia de marketing
2.4.1.1 Creación de materiales promocionales
2.4.1.2 Publicidad en medios
2.4.2 Gestión de redes sociales
2.4.2.1 Creación de contenido
2.4.2.2 Programación de publicaciones
2.5. Programa del evento
2.5.1 Elaboración del programa
2.5.1.1 Selección de oradores y presentadores
2.5.1.2 Creación de actividades interactivas
2.5.2 Coordinación de presentaciones
2.5.3 Pruebas de sonido y luces
2.6. Día del evento
2.6.1 Preparación del lugar
2.6.1.1 Decoración del espacio
2.6.1.2 Configuración de stands y expositores
2.6.2 Registro de invitados
2.6.3 Coordinación del flujo de invitados
2.6.4 Gestión de emergencias y primeros auxilios
2.7. Evaluación post-evento
2.7.1 Recopilación de comentarios y opiniones
2.7.2 Análisis del rendimiento del evento
2.7.3 Informe final y documentación
Proyecto 3: Investigación social empírica
3.0 Estudio sobre la calidad de vida en la Comunidad αβγ
3.1. Inicio del proyecto
3.1.1 Revisión de la propuesta de investigación
3.1.2 Definición de objetivos y preguntas de investigación
3.1.3 Creación del equipo de investigación
3.1.4 Desarrollo del marco teórico
3.2. Diseño de la investigación
3.2.1 Metodología de investigación
3.2.1.1 Selección de métodos cuantitativos y cualitativos
3.2.1.2 Diseño de instrumentos de recolección de datos
3.2.2 Muestra y selección de participantes
3.2.2.1 Determinación de criterios de inclusión y exclusión
3.2.2.2 Obtención de consentimientos éticos
3.2.3 Planificación de entrevistas y encuestas
3.2.3.1 Entrenamiento de entrevistadores
3.2.3.2 Preparación de cuestionarios
3.3. Recopilación de datos
3.3.1 Implementación de entrevistas y encuestas
3.3.1.1 Programación de entrevistas
3.3.1.2 Administración de encuestas
3.3.2 Trabajo de campo
3.3.2.1 Identificación de lugares de observación
3.3.2.2 Registro de observaciones
3.4. Análisis de datos
3.4.1 Transcripción de entrevistas
3.4.2 Codificación y categorización
3.4.3 Análisis estadístico (si aplica)
3.4.3.1 Uso de herramientas estadísticas
3.4.3.2 Interpretación de resultados
3.4.4 Interpretación de datos cualitativos
3.5. Elaboración de informe
3.5.1 Estructura del informe
3.5.1.1 Introducción
3.5.1.2 Revisión de literatura
3.5.1.3 Metodología
3.5.1.4 Resultados
3.5.1.5 Conclusiones y discusión
3.5.2 Redacción del informe final
3.5.3 Revisión por pares y correcciones
3.6. Presentación de resultados
3.6.1 Preparación de presentación
3.6.2 Creación de material visual
3.6.3 Planificación de la sesión de presentación
3.6.3.1 Invitación a stakeholders y comunidad
3.6.3.2 Logística del evento
3.7. Difusión y publicación
3.7.1 Preparación de resúmenes ejecutivos
3.7.2 Elaboración de artículos científicos
3.7.3 Envío a revistas especializadas
3.7.4 Publicación en medios de comunicación
3.8. Evaluación y reflexión del proyecto
3.8.1 Evaluación del proceso
3.8.2 Reflexión sobre limitaciones y lecciones aprendidas
3.8.3 Preparación para futuras investigaciones
Beneficios de utilizar la estructura de desglose del trabajo
No es difícil intuir que las ventajas de contar con una EDT de calidad tienen que ver con la claridad y el orden de la planificación del proyecto.
Vamos ahora a desglosar las ventajas del desglose:
Claridad y comprensión
La EDT nos proporciona una visión clara y detallada del proyecto y sus requerimientos, con lo cual se facilita la relación entre tareas y objetivos.
Asignación de recursos
Teniendo claridad sobre el desglose de tareas, la asignación de personal, tiempo y recursos de todo tipo resulta no sólo más sencilla, sino, sobre todo, más eficiente.
Estimación de costos
Al contar con un desglose en tareas pequeñas y asequibles, la estimación de costos se facilita notablemente. Esto también asegurará un mejor control financiero del proyecto.
Seguimiento y control
La EDT es una eficaz herramienta de seguimiento del progreso del proyecto. Las desviaciones quedarán en evidencia más rápidamente y ello permitirá aplicar de forma oportuna los ajustes pertinentes.
Comunicación efectiva
El desglose de tareas también potencia una comunicación eficaz entre los miembros del equipo y entre éste y los stakeholders. La codificación de los componentes de la EDT es un factor que facilita enormemente esta comunicación.
Riesgos en la aplicación de la EDT
Podemos afirmar que las ventajas de una buena EDT saltan a la vista. Sus riesgos, en cambio, son probablemente menos evidentes. Pero existen y es importante tenerlos presentes.
1º error: Confusión con el cronograma
Sabemos que un proyecto se define por su ciclo de vida acotado; es decir, todo proyecto tiene un inicio, desarrollo y final. Dicha naturaleza del proyecto puede llevarnos con bastante facilidad a pensar que el desglose de tareas es lo mismo que el cronograma. No es así. De hecho, el desarrollo de la EDT es previo a la elaboración del cronograma. Además, la EDT es una herramienta que facilita la asignación de tiempo a las diversas tareas.
2º error: Desglose excesivo
En el intento de conseguir una EDT meticulosa podríamos incurrir en un exceso de detalle. Diversos especialistas en la materia ofrecen diferentes recomendaciones para no caer en este error. Así, hay quienes recomiendan que cada paquete de trabajo corresponda a un 0,5% o más del presupuesto total del proyecto. Otros fijan el límite del desglose en el tiempo de trabajo de la persona responsable: cada elemento del nivel inferior de la EDT debería involucrar 80 o más horas/persona. El criterio aplicable se tendrá que definir en función de las características del proyecto: un proyecto de corto plazo permitirá un mayor nivel de detalle, mientras que un proyecto de más largo aliento requerirá una visión más general.
3º error: Utilización de herramientas poco eficaces
Son muchas las herramientas que ofrece el mercado digital para la gestión de proyectos y la elaboración de la EDT bien puede beneficiarse de ellas. El riesgo en este caso está en emplear una herramienta concebida para la gestión temporal del proyecto, para la elaboración de una carta Gantt o para el control de flujos de trabajo, como por ejemplo un tablero Kanban. Es cierto que la mayoría de herramientas de gestión podrían adaptarse para el desarrollo de una EDT, pero debemos cuidar que no se pierdan de vista los criterios de calidad del desglose.
4º error: Olvidar la orientación a entregables
Este riesgo está muy relacionado con el anterior. En el afán de meticulosidad, detalle y planificación podríamos acabar enfocándonos en los procesos y la gestión del tiempo, antes que en los entregables planificados para cada fase del proyecto y que son los que aportan valor al cliente.
Herramientas digitales para desarrollar la EDT
Ya lo apuntábamos unas líneas más arriba: son muchas las herramientas que nos ofrece el mercado digital y que pueden facilitar los esfuerzos necesarios para una eficaz gestión del proyecto. La elaboración y comunicación de la EDT también puede beneficiarse de algunas de estas herramientas.
Qué software pueda resultar más adecuado dependerá del nivel de complejidad del proyecto y del equipo de desarrollo, de los recursos disponibles o de nuestras propias competencias. Podemos ir desde un nivel de baja complejidad y altísima accesibilidad de la tecnología -como puede ser una herramienta de ofimática- hasta aplicaciones empresariales de lo más sofisticadas.
Aquí van algunas sugerencias.
Herramientas de ofimática
Desde el simple procesador de textos hasta la hoja de cálculo pueden ser de utilidad para ilustrar la matriz de una EDT.
Word, Google Docs, Pages o Writer tienen la gran ventaja de que son conocidos por todo el mundo y que los archivos se pueden compartir con facilidad, ya que son compatibles con la mayoría de plataformas. En cualquiera de estos procesadores de texto podríamos expresar la EDT tanto como un diagrama como en forma de lista multinivel; esta última tiene una gran ventaja desde el punto de vista de la accesibilidad. El inconveniente del uso de un procesador es que, si el proyecto es complejo, la comprensión del desglose podría dificultarse.
Una hoja de cálculo, como Excel, Google Sheets o Numbers, también puede ser de gran ayuda. En este caso la ventaja vendrá dada por la capacidad de organización y gestión de los datos. Ahora bien, claramente las hojas de cálculo están diseñadas para el trabajo con números, antes que con texto, por lo cual la comprensión del desglose y de las dependencias entre actividades podría llegar a resultar complicada.
Software de gestión de proyectos
Cualquier aplicación diseñada para la gestión de proyectos podría servir perfectamente para la elaboración de la EDT. Eso sí, tendremos que poner mucho cuidado en no perder de vista una de las condiciones que ya hemos enfatizado antes: el desglose de actividades no es lo mismo que el cronograma. Herramientas como Trello, Jira, Asana o Teams, por ejemplo, son sumamente eficientes en lo que toca a la gestión de flujos de trabajo y también a la colaboración en línea y tiempo real. Con la adaptación correspondiente, cualquiera de estas plataformas puede convertirse en nuestro asistente para el desglose de tareas, facilitando, además, la identificación de los grandes hitos del ciclo de vida del proyecto. Pero, repetimos, habrá que cuidar que nuestra EDT no se transforme en un cronograma, un tablero Kanban o un diagrama de Gantt, con lo cual estaríamos traicionando su cometido.
Soluciones ERP
Sin duda, las soluciones ERP están por encima de cualquier otro recurso en lo que se refiere a su capacidad de respuesta a cualquiera de las necesidades de la dirección de un proyecto. Un ejemplo de este tipo es SAP.
Dos grandes desventajas presenta este tipo de herramienta: la curva de aprendizaje que puede requerir, dada su complejidad, y su costo, al alcance sólo de empresas de cierto tamaño (aunque suelen ofrecer planes específicos para la PYME).
Conclusión
En resumen, la estructura de desglose del trabajo no puede estar ausente en la caja de herramientas de mimgún project manager. Su función es la de ayudar a que el proyecto resulte planificable, administrable y controlable. Además, la EDT potencia la comunicación eficaz entre equipo y partes interesadas. Una adecuada EDT facilitará la asignación de recursos y la planificación temporal de las actividades del proyecto y, especialmente, de los entregables.
Todo esto nos lleva a concluir que la EDT allana el camino al éxito del proyecto.
Notas y referencias
NOTA: Imagen de portada realizada con Dall.E.
- Raeburn, Alicia (2021, 22 de diciembre). EDT: cómo hacer una para tu proyecto con un ejemplo. Asana.com. En línea: https://asana.com/es/resources/work-breakdown-structure Acceso 05/02/2024.
- Norman, E. S., Brotherton, S., Fried, R. T., & Ksander, G. (2006). Building high quality work breakdown structures using the Practice standard for work breakdown structures—second edition. Paper presented at PMI® Global Congress 2006—North America, Seattle, WA. Newtown Square, PA: Project Management Institute. En línea: https://www.pmi.org/learning/library/practice-standard-work-breakdown-structures-8063 Acceso 05/02/2024.
Modelo INVEST: checklist
Guía para ayudar a aplicar el modelo INVEST en la redacción de historias de usuario.
Información
El modelo INVEST es un conjunto de criterios que deberían orientar la redacción de cada historia de usuario durante la elaboración del product backlog.
El propósito de esta checklist es ayudar a la aplicación del modelo INVEST. Respondiendo a una serie de preguntas podemos comprobar si cada criterio se está aplicando en la redacción de la user story.
Independent (independiente)
¿Se explica por sí sola y de forma autónoma respecto a las demás user stories del product backlog?
¿Se puede cambiar de posición en el product backlog sin alterar las otras user stories?
¿Se podría incluir en un sprint backlog con total independencia respecto al resto de user stories?
Negotiable (negociable)
¿Pueden participar cliente y equipo de desarrollo en la co-creación de la historia de usuario?
¿Expresa la esencia del requerimiento, sin entrar en detalles?
¿Admite la user story futuras actualizaciones, ya sea mediante notas o comentarios?
Valuable (valiosa)
¿Aporta valor al cliente?
¿La percibe el cliente como un aporte valioso?
Una vez desarrollada, ¿se percibirá netamente un cambio positivo?
Estimable (estimable)
¿Es posible expresar la historia de usuario en términos de puntos de esfuerzo u otra unidad de estimación?
¿Tiene el equipo de desarrollo la experiencia necesaria para estimar esta user story?
¿Podrá el equipo de desarrollo definir el tiempo o esfuerzo necesario para llevar a cabo las tareas que se desglosen de esta user story?
Small (pequeña)
¿Se puede redactar de forma breve y completa en una tarjeta?
¿Se podrá desarrollar la historia de usuario en un tiempo igual o inferior a un par de semanas de trabajo por persona?
¿Se comprende de forma fácil e inmediata cuál es el aporte de la historia al alcance del proyecto?
Testable (comprobable)
¿El cliente tiene claros los criterios de evaluación de la historia?
¿Son operativos los criterios de evaluación de la historia?
Los indicadores establecidos, ¿ayudan a evaluar si nos acercamos a los objetivos del proyecto?
Redacción de las historias de usuario
Recordemos que cada historia de usuario es un componente del product backlog de un proyecto desarrollado con un marco agile.
Para garantizar que las historias cumplan su cometido, se han elaborado algunos modelos y criterios, como INVEST, SMART o las 3C. En este caso nos hemos enfocado en el primero de estos modelos. Si tras la aplicación de la checklist todas las respuestas son afirmativas, podremos confiar que la historia está bien elaborada.
Notas y referencias
Imagen de portada elaborada mediante inteligencia artificial en Dall.E.